Peut-être l'avez vous remarqué, certains programmes en BASIC sont construits avec leur programme principal avec des numéros de ligne « hauts » et ont leurs traitements souvent appelés dans les lignes « basses ».
Ainsi, dans l'article précédent sur le listing, le programme commence par un GOTO 10000 et le décodage de ligne est en 1300. À vrai dire, avant que je ne stocke les adresses des tokens dans un tableau, le décodage systématique de leurs noms étaient dans des lignes encore plus basses.
La raison en est toute simple : lorsque le BASIC sur VG5000µ cherche un numéro de ligne, il le cherche systématiquement depuis le début du programme.
C'est où que ça cherche ?
La routine de recherche de ligne est en $2347 et est appelée par GOTO, RESTORE, RENUM (beaucoup !), LIST, AUTO (à chaque nouvelle ligne), NEW, mais aussi lorsqu'il s'agit d'insérer une nouvelle ligne dans le listing au bon endroit, voire de remplacer une ancienne.
Pour appeler cette routine, il suffit d'assigner à DE le numéro de ligne recherché.
line_search: ld bc,$0000
ld hl,(txttab)
line_search_lp:
ld (prelin),bc
ld b,h
ld c,l
ld a,(hl)
inc hl
or a,(hl)
dec hl
ret z
inc hl
inc hl
ld a,(hl)
inc hl
ld h,(hl)
ld l,a
rst de_compare
ld h,b
ld l,c
ld a,(hl)
inc hl
ld h,(hl)
ld l,a
ccf
ret z
ccf
ret nc
jr line_search_lp
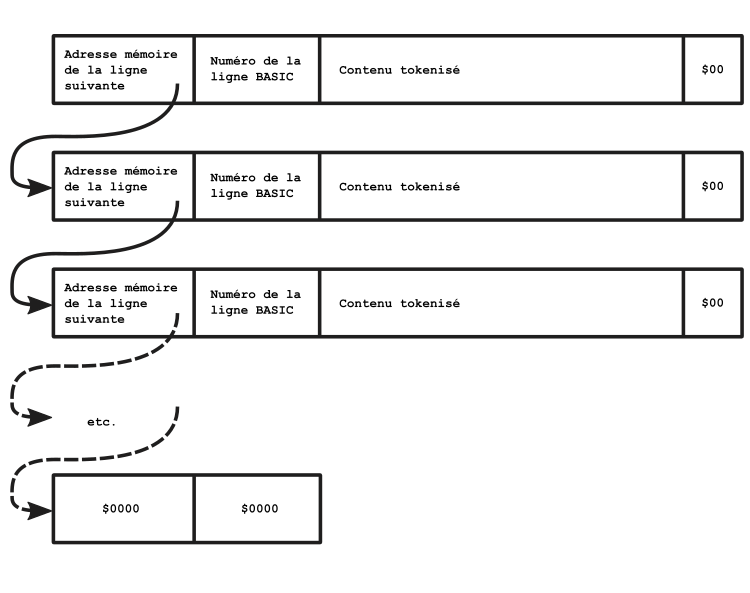
Tout commence avec l'initialisation de BC avec $0000 et de HL avec le pointeur de début de listing. Puis débute la boucle de recherche.
En début de boucle, la ligne contenue dans BC est stocké dans une variable système prelin. Cette variable système contiendra en tout temps le dernier numéro de ligne qui a été trouvé dans le listing.
Jusqu'au RET Z, il s'agit de lire le contenu du pointeur de ligne suivante et vérifier s'il est égal à $0000. Si c'est le cas, ce RET Z provoque la fin de la routine. Le Carry Flag est à 0 grâce au OR qui précède, ce qui indiquera que la ligne n'a pas été trouvée.
Pour rappel, une ligne de BASIC stockée en mémoire commence par un pointeur de chaînage vers la ligne suivante, ou $0000 s'il s'agit de la dernière ligne.
On peut être surpris par ce DEC HL avant le retour de la routine, compensé par le premier INC HL juste après le RET Z. Comme le BASIC sauve un octet en fusionnant les 4 octets nuls terminant le chaînage des lignes avec le $00 d'une fin de ligne, le pointeur, qui est un cran après ce $00 de fin de ligne, réintègre le besoin des 4 octets nuls de fin de chaînage.
Mais si on ne sort pas de la routine, alors cet octet n'est pas fusionné, il faut remettre HL à sa place initiale.
Après le RET Z, le numéro de la ligne BASIC, qui est dans la ligne BASIC stockée formé par les deux octets suivants, est lu dans HL. Puis comparé à DE via RST DE_COMPARE.
En se souvenant que le numéro de ligne recherché est dans DE, après cette comparaison, il y a trois cas :
HLetDEsont égaux : on a donc trouvé la ligne. Le flagZest mis à1, le Carry Flag est à0HLest supérieur àDE: on a trouvé un numéro de ligne plus grand que celui recherché. La ligne recherchée n'existe donc pas.Zest à0,Carryest à0aussi.HLest inférieur àDE: il faut continuer à chercher.Zest à0,Carryest à1.
Après la comparaison, HL est remis à l'adresse sauvée en début de boucle dans BC, pour revenir sur l'adresse de chaînage. Cette adresse est celle de la ligne que l'on vient de valider comme étant la suivante (voire la bonne !), l'adresse est donc lue à nouveau dans HL.
Les lignes suivantes traitent les différents cas de comparaison de ligne.
Tout d'abord le couple CCF / RET Z fait sortir la routine si la ligne a été trouvée. CCF qui inverse la valeur du Carry Flag, le met donc à 1 dans le cas où Z était à 1. En sortie de routine, le Carry Flag à 1 indique que la ligne a été trouvée. HL pointe sur le début de la zone de cette ligne.
Puis le couple CCF / RET NC remet le Carry Flag a son état d'après la comparaison entre HL et DE et le test. Dans le cas où la ligne n'est pas là, on sort de la routine, mais donc cette fois avec le Carry Flag à 0, indiquant que la ligne n'a pas été trouvée. HL pointe alors vers l'adresse de la ligne suivante, et BC sur la ligne précédente. C'est intéressant dans le cas où l'on veut chaîner une nouvelle ligne entre les deux.
Si aucun de ces cas de sortie n'a eu lieu, le JR final repart pour un nouveau tour de boucle.
Et NEXT et RETURN ?
NEXT et RETURN sont deux instructions qui provoquent une rupture de séquence. Autrement dit, suite à leur exécution, l'exécution continue ailleurs. En début de boucle si la boucle n'est pas terminée avec NEXT, ou après le GOSUB dans le cas du RETURN.
Le fonctionnement de ces instructions est différent. FOR et GOSUB vont placer le pointeur sur les instructions en train d'être interprétées dans un endroit sûr. GOSUB le place sur la pile, FOR aussi... si des FOR sont imbriqués, sinon, dans une variable système spécifique (endfor).
Lorsqu'il faut reprendre l'exécution, le pointeur vers l'instruction en cours en remis à la valeur sauvegardée (avec son numéro de ligne correspondant, une autre variable système à garder cohérente, (curlin)) puis le décodage continue.
Par conséquent, les boucles FOR/NEXT et un RETURN ne sont pas affectés par la recherche de numéro de ligne.
Ça optimise ?
Choisir pour des destinations de saut de numéros de lignes les plus proches du début du programme est donc une optimisation. Mais soyons franc, c'est une toute petite optimisation. La recherche par parcours de liste chaînée est rapide en assembleur en comparaison de l’évaluation d'une expression un peu complexe avec des variables à manipuler par exemple.
J'ai pu lire que sur certains BASICs d'autres machines, une optimisation avait été faite par le simple fait de rechercher la ligne de destination par rapport à la ligne actuelle, privilégiant ainsi la localité des sauts. Est-ce que cela serait efficace sur la ROM VG5000µ ? Peut-être... à suivre.